El inicio de una nueva era de inteligencia avanzada
El 18 de noviembre de 2025 quedó marcado como un día decisivo en la historia de la inteligencia artificial: Google DeepMind presentó Gemini 3, su modelo más avanzado hasta la fecha. No se trata sólo de una mejora incremental: es una plataforma que entiende, razona, crea y actúa con una capacidad hasta ahora poco vista, y que promete cambiar cómo trabajamos, aprendemos y producimos contenido.
Demis Hassabis, CEO de Google DeepMind, lo resumió así: “Gemini 3 es nuestro modelo más capaz, pensado para ayudarte a materializar cualquier idea.” El modelo integra y amplía las capacidades de generaciones previas en un sistema unificado pensado para aplicaciones reales y complejas.
¿Qué es Gemini 3? Un salto cualitativo
Tras casi dos años de trabajo desde el inicio de la era Gemini, Google ha acumulado hitos importantes que preparan el terreno para este lanzamiento:
- 2.000 millones de usuarios mensuales usan AI Overviews.
- 650 millones de usuarios mensuales en la app Gemini.
- Más del 70% de clientes de Google Cloud aprovechan IA.
- 13 millones de desarrolladores han construido con los modelos generativos de Google.
Gemini 3 se posiciona como el modelo líder mundial en comprensión multimodal y es el más potente hasta ahora para tareas de codificación y agentes autónomos, ofreciendo mayor interactividad y visualizaciones más ricas basadas en razonamiento avanzado.
Capacidades clave de Gemini 3
1. Razonamiento de vanguardia
Gemini 3 Pro bate marcas en benchmarks de alto nivel:
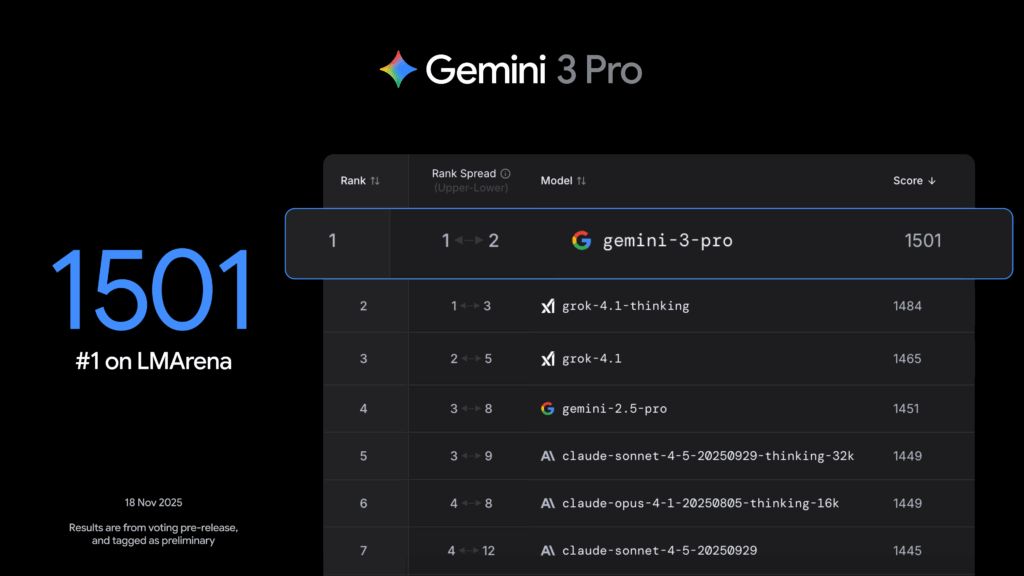
- Lidera LMArena con 1501 Elo, mostrando un nivel de razonamiento comparable al académico avanzado.
- 37.5% en Humanity’s Last Exam (sin herramientas) y 91.9% en GPQA Diamond.
- 23.4% en MathArena Apex, nuevo referente en problemas matemáticos complejos.
- 81% en MMMU-Pro y 87.6% en Video-MMMU, destacando su dominio multimodal.
- 72.1% en SimpleQA Verified en precisión factual.
- 45.1% en ARC-AGI-2 con ejecución de código, un hito en resolución de retos novedosos.
Además, es mucho mejor interpretando contexto e intención, de modo que requiere menos instrucciones explícitas para obtener respuestas útiles.
2. Ventana de contexto gigantesca: 1 millón de tokens
Gemini 3 puede procesar conjuntos enormes de información de una sola vez: proyectos completos de código, documentos extensos, conversaciones prolongadas o cientos de páginas manteniendo coherencia y precisión.
3. Multimodalidad nativa
Entiende y combina datos de distintas fuentes: texto, imágenes, vídeo, audio y código. Esa capacidad le permite abordar problemas complejos que requieren perspectivas integradas.
4. Generative UI — interfaces visuales generadas por IA
Una innovación destacada: en lugar de solo texto, Gemini 3 puede producir interfaces visuales dinámicas a medida, por ejemplo:
- Interfaces visuales personalizadas según la consulta.
- Simuladores interactivos manipulables en tiempo real.
- Tablas y visualizaciones generadas automáticamente.
- Itinerarios visuales (viajes, proyectos) y calculadoras interactivas.
- Presentaciones tipo revista con módulos, fotos y elementos interactivos.
En pruebas de preferencia, estas UIs creadas por la IA compiten estrechamente con diseños hechos por expertos humanos.
5. Deep Think — modo de pensamiento profundo
Un modo especial de razonamiento que potencia aún más su capacidad analítica:
- 41.0% en Humanity’s Last Exam (sin herramientas).
- 93.8% en GPQA Diamond.
- 45.1% en ARC-AGI-2 con ejecución de código.
Deep Think está pensado para tareas que requieren reflexión y deliberación antes de ofrecer una respuesta.

Gemini 3 representa, en conjunto, un avance significativo en comprensión multimodal, razonamiento y generación de experiencias interactivas. Su combinación de gran contexto, multimodalidad y nuevas formas de salida (como Generative UI) lo sitúan como una plataforma preparada para transformar múltiples industrias y flujos de trabajo.